我们的下一代型号:Gemini 1.5

谷歌和 Alphabet 首席执行官桑达尔·皮查伊 (Sundar Pichai) 的注释:
上周,我们推出了功能最强大的模型 Gemini 1.0 Ultra,并从Gemini Advanced开始,在让 Google 产品变得更加有用方面向前迈出了重要一步。今天,开发人员和云客户也可以开始使用 1.0 Ultra 进行构建——使用AI Studio和Vertex AI中的 Gemini API 。
我们的团队以安全为核心,继续推动最新型号的发展。他们正在快速进步。事实上,我们已经准备好推出下一代产品:Gemini 1.5。它在多个维度上都显示出显着的改进,并且 1.5 Pro 实现了与 1.0 Ultra 相当的质量,同时使用更少的计算。
新一代在长上下文理解方面也取得了突破。我们已经能够显着增加模型可以处理的信息量——持续运行多达 100 万个令牌,实现迄今为止任何大型基础模型中最长的上下文窗口。
更长的上下文窗口向我们展示了可能性的希望。它们将实现全新的功能,并帮助开发人员构建更有用的模型和应用程序。我们很高兴向开发人员和企业客户提供此实验性功能的有限预览。Demis 在下面分享了有关功能、安全性和可用性的更多信息。
— 桑达尔
双子座 1.5 简介
作者:Demis Hassabis,Google DeepMind 首席执行官,代表 Gemini 团队
对于人工智能来说,这是一个激动人心的时刻。该领域的新进展有可能使人工智能在未来几年为数十亿人提供更多帮助。自从推出 Gemini 1.0以来,我们一直在测试、完善和增强其功能。
今天,我们宣布推出下一代型号:Gemini 1.5。
Gemini 1.5 显着增强了性能。它代表了我们方法的一步改变,建立在我们基础模型开发和基础设施几乎每个部分的研究和工程创新的基础上。这包括通过新的专家混合(MoE) 架构使 Gemini 1.5 的训练和服务更加高效。
我们发布用于早期测试的第一个 Gemini 1.5 型号是 Gemini 1.5 Pro。它是一个中型多模式模型,针对广泛的任务进行了优化,其性能水平与我们迄今为止最大的模型1.0 Ultra 类似。它还引入了长上下文理解方面的突破性实验特征。
Gemini 1.5 Pro 配备了标准的 128,000 令牌上下文窗口。但从今天开始,少数开发人员和企业客户可以通过AI Studio和Vertex AI 的私人预览版在最多 100 万个代币的上下文窗口中进行尝试。
当我们推出完整的 100 万个令牌上下文窗口时,我们正在积极进行优化,以改善延迟、减少计算要求并增强用户体验。我们很高兴人们尝试这一突破性功能,我们将在下面分享有关未来可用性的更多详细信息。
我们下一代模型的这些持续进步将为人们、开发人员和企业使用人工智能进行创造、发现和构建开辟新的可能性。
领先基础模型的上下文长度
高效架构
Gemini 1.5 建立在我们对Transformer和MoE架构的领先研究之上。传统 Transformer 充当一个大型神经网络,而 MoE 模型则分为更小的“专家”神经网络。
根据给定输入的类型,MoE 模型学会选择性地仅激活其神经网络中最相关的专家路径。这种专业化极大地提高了模型的效率。通过稀疏门控 MoE、GShard-Transformer、Switch-Transformer、 M4等研究,Google 一直是深度学习 MoE 技术的早期采用者和先驱。
我们在模型架构方面的最新创新使 Gemini 1.5 能够更快地学习复杂任务并保持质量,同时更高效地训练和服务。这些效率正在帮助我们的团队比以往更快地迭代、培训和交付更高级的 Gemini 版本,并且我们正在努力进一步优化。
更大的背景,更有用的功能
人工智能模型的“上下文窗口”由令牌组成,令牌是用于处理信息的构建块。令牌可以是文字、图像、视频、音频或代码的整个部分或子部分。模型的上下文窗口越大,它在给定提示中可以接收和处理的信息就越多,从而使其输出更加一致、相关和有用。
通过一系列机器学习创新,我们增加了 1.5 Pro 的上下文窗口容量,远远超出了 Gemini 1.0 最初的 32,000 个令牌。我们现在可以在生产环境中运行多达 100 万个代币。
这意味着 1.5 Pro 可以一次性处理大量信息,包括 1 小时的视频、11 小时的音频、超过 30,000 行代码或超过 700,000 个单词的代码库。在我们的研究中,我们还成功测试了多达 1000 万个代币。
对大量信息进行复杂推理
1.5 Pro 可以在给定提示内无缝分析、分类和总结大量内容。例如,当给出阿波罗 11 号登月任务的 402 页记录时,它可以推理整个文档中的对话、事件和细节。
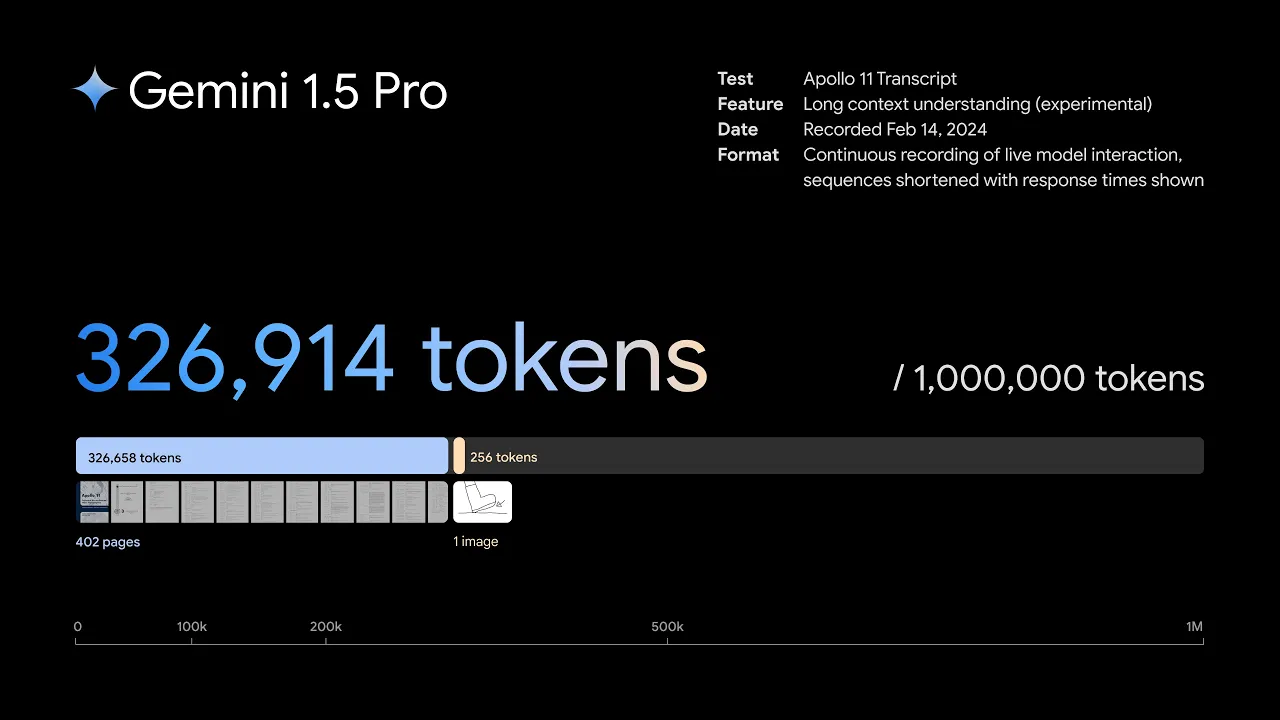
Gemini 1.5 Pro 可以理解、推理和识别阿波罗 11 号登月任务的 402 页记录中的好奇细节。
更好地理解和推理跨模式
1.5 Pro 可以针对包括视频在内的不同模式执行高度复杂的理解和推理任务。例如,当给定一部 44 分钟的巴斯特·基顿无声电影时,该模型可以准确分析各种情节点和事件,甚至推理出电影中容易被忽略的小细节。
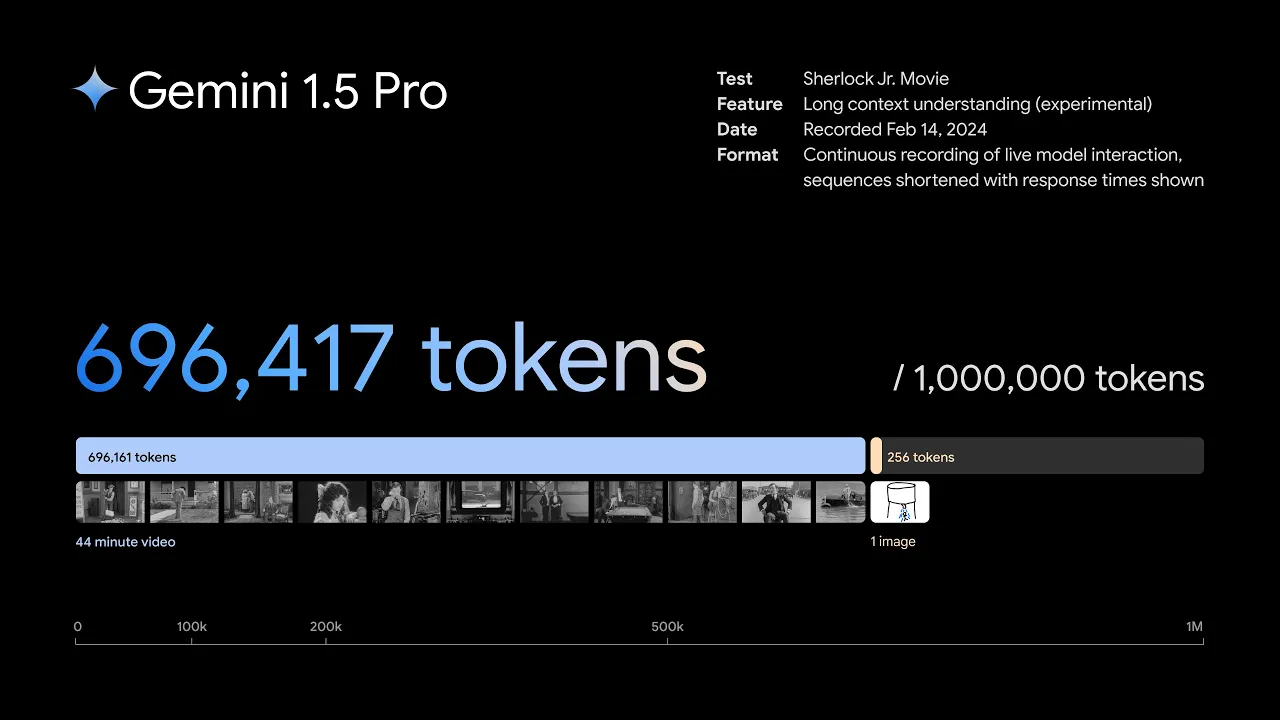
当给出简单的线条图作为现实生活中物体的参考材料时,Gemini 1.5 Pro 可以识别 44 分钟的巴斯特基顿无声电影中的场景。
使用较长的代码块解决相关问题
1.5 Pro 可以跨较长的代码块执行更相关的问题解决任务。当给出超过 100,000 行代码的提示时,它可以更好地推理示例、建议有用的修改并解释代码不同部分的工作原理。
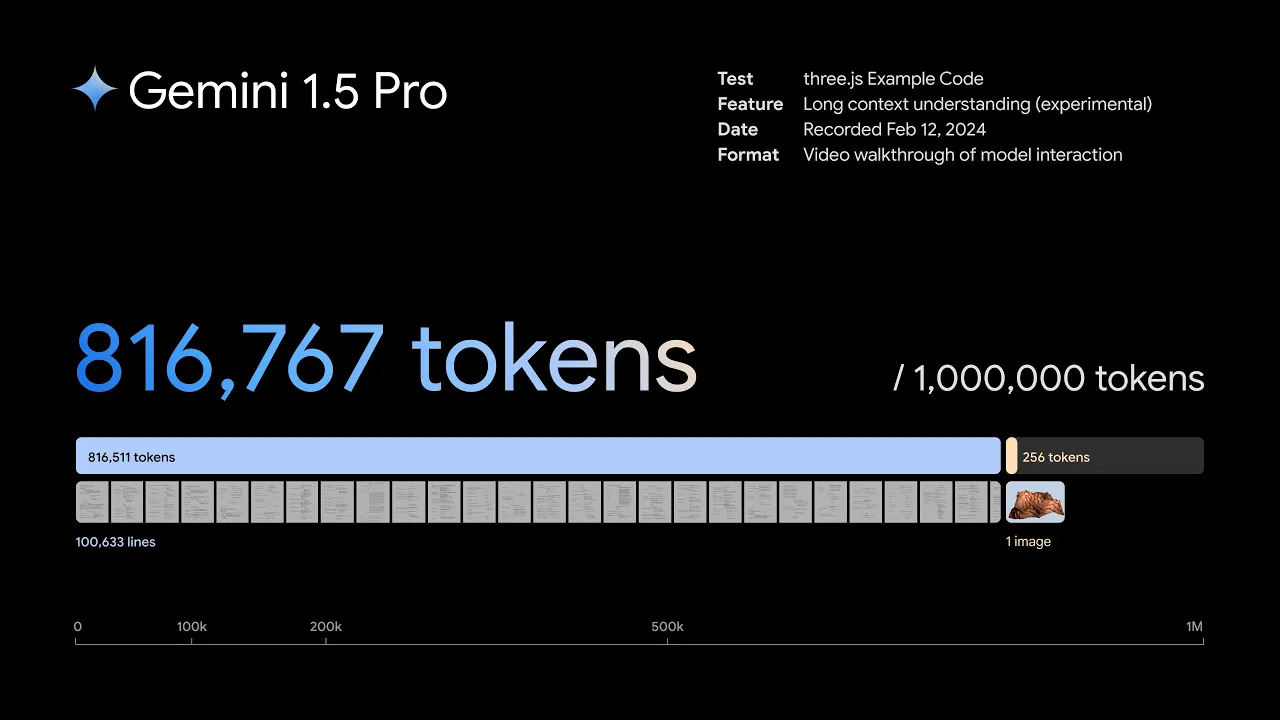
Gemini 1.5 Pro 可以推理 100,000 行代码,提供有用的解决方案、修改和解释。
增强性能
当在文本、代码、图像、音频和视频评估的综合面板上进行测试时,1.5 Pro 在用于开发大型语言模型 (LLM) 的基准测试中 87% 的表现优于 1.0 Pro。在相同的基准测试中与 1.0 Ultra 相比,它的表现大致相似。
即使上下文窗口增加,Gemini 1.5 Pro 仍能保持高水平的性能。在大海捞针(NIAH) 评估中,故意将包含特定事实或陈述的一小段文本放置在很长的文本块中,1.5 Pro 99% 的时间都能找到嵌入文本,数据块如下只要100万个代币。
Gemini 1.5 Pro还展示了令人印象深刻的“情境学习”技能,这意味着它可以从长提示中给出的信息中学习新技能,而不需要额外的微调。我们在《一本书的机器翻译》 (MTOB) 基准测试中测试了这项技能,该基准显示了该模型从以前从未见过的信息中学习的能力。当给定卡拉曼语(一种全球使用人数不足 200 人的语言)的语法手册时,该模型可以学习将英语翻译成卡拉曼语,其水平与学习相同内容的人相似。
由于 1.5 Pro 的长上下文窗口是大型模型中的首创,因此我们正在不断开发新的评估和基准来测试其新颖的功能。
有关更多详细信息,请参阅我们的Gemini 1.5 Pro 技术报告。
广泛的道德和安全测试
根据我们的人工智能原则和强大的安全政策,我们确保我们的模型经过广泛的道德和安全测试。然后,我们将这些研究成果整合到我们的治理流程以及模型开发和评估中,以不断改进我们的人工智能系统。
自 12 月推出 1.0 Ultra 以来,我们的团队不断完善该模型,使其更安全,适合更广泛的发布。我们还对安全风险进行了新颖的研究,并开发了红队技术来测试一系列潜在危害。
在发布 1.5 Pro 之前,我们采取了与 Gemini 1.0 模型相同的负责任部署方法,在内容安全和代表性危害等领域进行了广泛的评估,并将继续扩大这一测试。除此之外,我们正在开发进一步的测试,以解释 1.5 Pro 新颖的长上下文功能。
使用 Gemini 模型进行构建和实验
我们致力于负责任地将每一代新一代 Gemini 模型带给全球数十亿人、开发者和企业。
从今天开始,我们将通过AI Studio和Vertex AI向开发人员和企业客户提供 1.5 Pro 的有限预览版。请在我们的Google for Developers 博客和Google Cloud 博客上了解更多相关信息。
当模型准备好进行更广泛的发布时,我们将推出具有标准 128,000 个令牌上下文窗口的 1.5 Pro。很快,随着我们改进模型,我们计划引入从标准 128,000 个上下文窗口开始并扩展到 100 万个代币的定价等级。
早期测试人员可以在测试期间免费尝试 100 万个令牌上下文窗口,尽管他们应该预计此实验功能的延迟时间会更长。速度的显着提高也即将到来。
有兴趣测试 1.5 Pro 的开发人员现在可以在 AI Studio 中注册,而企业客户可以联系他们的 Vertex AI 客户团队。
详细了解Gemini 的功能并了解其工作原理。