LLaVA-1.6:改进推理、OCR 和世界知识
今天,我们很高兴推出 LLaVA-1.6,它具有改进的推理、OCR 和世界知识。LLaVA-1.6 在多项基准测试中甚至超过了 Gemini Pro。
与LLaVA-1.5相比,LLaVA-1.6有几个改进:
- 将输入图像分辨率增加至 4 倍像素。这使得它能够掌握更多的视觉细节。它支持三种宽高比,最高可达672x672、336x1344、1344x336分辨率。
- 通过改进的视觉指令调整数据混合,提供更好的视觉推理和 OCR 功能。
- 更好的视觉对话,更多场景,覆盖不同应用。更好的世界知识和逻辑推理。
- 使用SGLang进行高效部署和推理。
除了性能改进之外,LLaVA-1.6 保持了 LLaVA-1.5 的极简设计和数据效率。它重新使用了 LLaVA-1.5 的预训练连接器,并且仍然使用不到 1M 的视觉指令调优样本。最大的 34B 型号在大约 1 天内完成了 32 架 A100 的训练。代码、数据、模型将公开。
开源版本
我们开源LLaVA-1.6,以促进LMM在社区的未来发展。代码、数据、模型将公开。
结果
开源 所有权
数据(PT)数据(信息技术)模型MMMU(有效值)数学VistaMMB-ENGMMB-CNMM-兽医LLaVA-狂野种子IMG不适用不适用GPT-4V56.849.975.873.967.6-71.6不适用不适用双子座超59.453-----不适用不适用双子座专业版47.945.273.674.364.3-70.71.4B50公尺Qwen-VL-Plus45.243.3--55.7-65.71.5B5.12MCogVLM-30B32.1---56.8--125M〜1M易-VL-34B45.9------558K665KLLaVA-1.5-13B36.427.667.863.336.372.568.2558K760KLLaVA-1.6-34B51.146.579.37957.489.675.9
✨亮点:
- 索塔性能!与CogVLM或Yi-VL等开源 LMM 相比,LLaVA-1.6 实现了最佳性能。与商用产品相比,它在选定的基准测试中赶上 Gemini Pro 并优于Qwen-VL-Plus。
- 中国零射击能力。LLaVA-1.6的中文能力是一种新兴的零样本能力(即仅考虑英文多模态数据)。它在中国多式联运场景上的表现出奇的好,例如MMBench-CN上的SoTA。
- 培训成本低。LLaVA-1.6 使用 32 个 GPU 训练约 1 天,总共 130 万个数据样本。计算/训练数据成本比其他方法小 100-1000 倍。
定性结果
马克·扎克伯格谈论 Llama-3 和 600K H100
根据航班信息什么时候出发去接机?

详细的技术改进
我们详细介绍了我们对 LLaVA-1.5 的发现和改进。更多实施细节将在未来几天发布并记录在此处。
(1) 动态高分辨率
我们以高分辨率设计模型,旨在保持其数据效率。当提供高分辨率图像和保留这些细节的表示时,模型感知图像中复杂细节的能力会显着提高。它减少了面对低分辨率图像时猜测想象的视觉内容的模型幻觉。我们的“AnyRes”技术旨在适应各种高分辨率的图像。我们采用网格配置{ 2 × 2 , 1 × { 2 , 3 , 4 } , { 2 , 3 , 4 } × 1 }
{2×2,1×{2,3,4},{2,3,4}×1},平衡性能效率与运营成本。有关更多详细信息,请参阅我们更新的 LLaVA-1.5 技术报告。
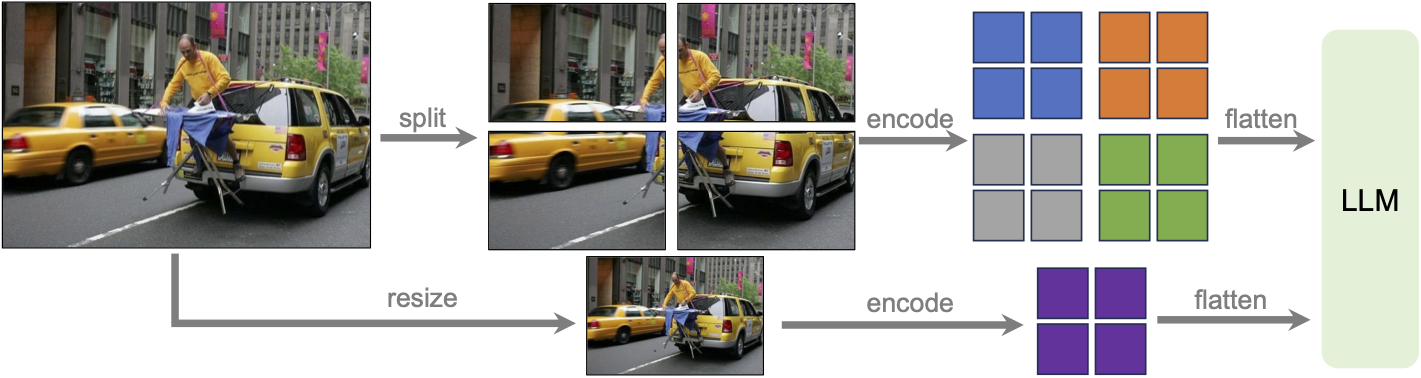
动态高分辨率方案的图示:网格配置2 × 2
2
×
2
(2) 数据混合
- 高质量的用户指令数据。我们对高质量视觉指令遵循数据的定义取决于两个主要标准:首先,任务指令的多样性,确保充分代表现实场景中可能遇到的广泛用户意图,特别是在模型运行期间。部署阶段。其次,响应的优越性至关重要,目的是征求有利的用户反馈。为了实现这一目标,我们考虑两个数据源:(1)现有的 GPT-V 数据。LAION-GPT-V和ShareGPT-4V。(2) 为了进一步促进更多场景下更好的视觉对话,我们收集了一个涵盖不同应用的小型 15K 视觉指令调优数据集。说明和图像来自LLaVA 演示,这是真实世界用户的请求。我们仔细过滤可能存在隐私问题或可能有害的样本,并使用 GPT-4V 生成响应。
- 多模式文档/图表数据。(1) 我们从训练数据中删除TextCaps ,因为我们意识到 TextCaps 使用与TextVQA相同的训练图像集。这使我们能够在开发过程中评估 TextVQA 时更好地了解模型的零样本 OCR 功能。为了保持并进一步提高模型的 OCR 能力,我们用 DocVQA 和 SynDog-EN 替换 TextCaps。(2) 在Qwen-VL-7B-Chat的推动下,我们进一步添加了 ChartQA、DVQA 和 AI2D,以更好地理解图表和图表。
(3) 扩展LLM骨干
除了Vicuna-1.5(7B和13B)之外,我们还考虑更多的LLM,包括Mistral-7B和Nous-Hermes-2-Yi-34B。这些法学硕士拥有良好的性质、灵活的商业使用条款、强大的双语支持和更大的语言模型容量。它让LLaVA能够支持社区更广泛的用户和更多的场景。LLaVA 配方适用于各种 LLM,并且可以顺利扩展到 34B 的 LLM。
型号卡
姓名LLaVA-1.6-7BLLaVA-1.6-13BLLaVA-1.6-34B型号尺寸全部的7.06B13.35B34.75B视觉编码器303.5M303.5M303.5M连接器21M31.5M58.7M法学硕士6.74B13B34.39B解决336 x [(2,2), (1,2), (2,1), (1,3), (3,1), (1,4), (4,1)]阶段1训练数据558K可训练模块连接器第二阶段训练数据760K可训练模块全模型计算(#GPU x #Hours)8x2016x2432x30训练数据(#Samples)1318K
团队
- 刘昊天: 威斯康星大学麦迪逊分校

- 李春元:字节跳动/抖音
 (部分工作在微软研究院完成)
(部分工作在微软研究院完成) - 李宇恒:威斯康星大学麦迪逊分校

- 李波:南洋理工大学
 (与字节跳动/TikTok合作)
(与字节跳动/TikTok合作) - 张渊涵:南洋理工大学
 (与字节跳动/TikTok合作)
(与字节跳动/TikTok合作) - 沉盛:加州大学伯克利分校

- 李龙在:威斯康星大学麦迪逊分校

致谢
- A16Z 开源人工智能资助计划。
- 我们感谢郑连民、盛颖、曹十一将 LLaVA 集成到 SGLang。
- 这项工作得到了 NSF CAREER IIS2150012、Microsoft Accelerate Foundation Models Research 以及韩国政府 (MSIT) 资助的信息与通信技术规划与评估研究所 (IITP) 赠款的部分支持(编号 2022-0-00871,开发AI 自主性和 AI 代理协作的知识增强)和(编号 RS-2022-00187238,开发用于高效预训练的大型韩语模型技术)。
引文
@misc{liu2024llava16,
title={LLaVA-1.6: Improved reasoning, OCR, and world knowledge},
url={https://llava-vl.github.io/blog/2024-01-30-llava-1-6/},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae},
month={January},
year={2024}
}
@misc{liu2023improvedllava,
title={Improved Baselines with Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
publisher={arXiv:2310.03744},
year={2023},
}
@misc{liu2023llava,
title={Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
publisher={NeurIPS},
year={2023},
}