傻瓜逆向 - x86 汇编和 C 代码(初学者/ADHD 友好的)
在我进入逆向工程之前,可执行文件似乎总是 对我来说就像黑魔法。 我一直想知道下面的东西是如何工作的 hood,以及二进制代码如何在 .exe 文件内表示,以及如何 在不访问的情况下修改这个“编译代码”是很困难的 原始源代码。
但主要的令人生畏的障碍之一似乎始终是 汇编语言,这是让大多数人望而却步的东西 试图了解这个领域。
这就是我想写这篇文章的主要原因 直接开门见山的文章,只包含基本内容 倒车时最常遇到的,尽管错过了关键的 为简洁起见,详细说明,并假设读者有条件反射 在线寻找答案、查找定义等等 重要的是,提出要练习的示例/想法/项目。
目标是希望指导有抱负的逆向工程师和 激发人们更多地了解这个看似难以捉摸的事物的动力 热情。
注意 :本文假设读者具备基础知识 关于 十六进制数字系统 ,以及 C 编程语言 ,基于 32 位 Windows 可执行案例研究 - 结果 不同操作系统/架构之间可能有所不同。
介绍
汇编
使用a编写代码后 编译语言 ,进行编译 (废话) ,为了生成 输出二进制文件(例如 .exe 文件)。

编译器是执行此任务的复杂程序。 他们做了 确定你的语法 丑陋的 代码是正确的,之前 通过最小化来编译和优化生成的机器代码 其尺寸并改进其性能(只要适用)。
二进制代码
正如我们所说,生成的输出文件包含二进制代码, 它只能被CPU“理解”,它本质上是一个 一系列不同长度的指令按顺序执行 - 其中一些是这样的:
CPU可读指令数据(十六进制) 人类可读的解释 55 推送ebp 8B欧共体 移动 ebp, esp 83 欧共体 08 子特别,8 33C5 异或 eax, ebp 83 7D 0C 01 cmp 双字指针 [ebp+0Ch], 1 这些指令主要是算术指令,并且它们 操作 CPU 寄存器/标志以及易失性存储器,如 他们被处决了。
CPU寄存器
一个CPU寄存器 几乎就像一个临时整数变量 - 有一个小的固定 它们的数量,它们存在是因为它们可以快速访问, 与基于内存的变量不同,它们帮助 CPU 跟踪 执行期间的数据(结果、操作数、计数等)。
重要的是要注意一个特殊寄存器的存在,称为 FLAGS登记 ( EFLAGS在 32 位),其中包含一堆标志(布尔指示器), 保存有关 CPU 状态的信息,其中包括详细信息 关于最后一次算术运算(零: ZF, 溢出: OF, 平价: PF, 符号: SF, ETC。)。
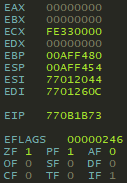 在调试 32 位进程时可视化 CPU 寄存器 x64dbg,一个调试工具。
在调试 32 位进程时可视化 CPU 寄存器 x64dbg,一个调试工具。
其中一些寄存器也可以在汇编摘录中找到 提到过 前面 ,即: EAX, ESP(堆 指针)和 EBP(根据 指针)。
内存访问
当 CPU 执行任务时,它需要访问并交互 内存,这时候 栈 和 堆 来了。
这些是(不涉及太多细节)的两种主要方法 在程序执行期间“跟踪变量数据”:
🥞 堆栈
两者中更简单、更快的 - 它是线性连续的 LIFO (后进=先出)具有push/pop机制的数据结构,它 用于记住函数范围的变量、参数并保留 通话轨迹(曾经听说过 堆栈跟踪 ?)
⛰ 堆
然而,堆是相当无序的,并且适用于更复杂的情况 数据结构,它通常用于动态分配,其中 缓冲区的大小最初未知,和/或是否太大 大,和/或需要稍后修改。
组装说明
正如我之前提到的,汇编指令有不同的 “字节大小”和不同数量的参数。
参数也可以是直接的(“硬编码”),也可以是 寄存器,取决于指令:
55 push ebp ; size: 1 byte, argument: register 6A 01 push 1 ; size: 2 bytes, argument: immediate
让我们快速浏览一下一小部分常见的内容 我们将会看到 - 请随意进行自己的研究以获得更多信息 细节:
堆栈操作
- 推 value ; 将一个值压入堆栈(递减 ESP经过 4、一堆“单元”的大小)。
- 流行音乐 register ; 将值弹出到寄存器(递增 ESP经过 4).
数据传输
- 移动 destination, source ; 动作 从/向寄存器复制一个值。
- 移动 destination, [ expression] ; 从“寄存器”解析的内存地址复制一个值 表达式'(单个寄存器或涉及的算术表达式 一个或多个寄存器)到一个寄存器中。
流量控制
- 跳跃 destination; 跳转到代码位置(设置 EIP (指令指针))。
- jz/是 destination; 跳转到代码位置如果 ZF (零标志)已设置。
- 津南/津尼 destination; 跳转到代码位置如果 ZF是 没有设置。
运营
- CMP operand1, operand2; 比较 2 个操作数并设置 ZF如果 他们是平等的。
- 添加 operand1, operand2; 操作数1 += 操作数2;
- 子 operand1, operand2; 操作数1 -= 操作数2;
功能转换
- 称呼 function; 调用一个函数(推送当前 EIP, 然后跳转到该函数)。
- 保留 ; 返回到调用者函数(弹出前一个 EIP)。
注意 :您可能会注意到使用了“等于”和“零”这两个词 在 x86 术语中可以互换 - 这是因为比较 指令内部执行减法,这意味着如果 2 操作数相等, ZF已设置。
装配模式
现在我们已经大致了解了过程中使用的主要元素 程序的执行,让我们熟悉一下模式 您可能会遇到的说明,对您的平均值进行逆向工程 日常32位 聚乙烯醇 二进制。
功能序言
A 函数序言 是嵌入在大多数函数开头的一些初始代码,它 用于为该函数设置一个新的堆栈框架。
它通常看起来像这样(X 是一个数字):
55 push ebp ; preserve caller function's base pointer in stack 8B EC mov ebp, esp ; caller function's stack pointer becomes base pointer (new stack frame) 83 EC XX sub esp, X ; adjust the stack pointer by X bytes to reserve space for local variables
函数尾声
这 结语 与序言完全相反——它撤消了其步骤 在返回之前恢复调用函数的堆栈帧 它:
8B E5 mov esp, ebp ; restore caller function's stack pointer (current base pointer) 5D pop ebp ; restore base pointer from the stack C3 retn ; return to caller function
现在,您可能想知道 - 函数如何与 彼此? 调用时如何发送/访问参数 函数,以及如何接收返回值? 正是如此 为什么我们有调用约定。
调用约定:__cdecl
A 调用约定 基本上是一个用于与函数通信的协议,有 它们有一些变体,但它们具有相同的原理。
我们将关注 __cdecl(C 声明)约定 ,这是编译 C 代码时的标准约定。
在 __cdecl(32 位)中,函数参数在堆栈上传递 (按相反顺序推送),而返回值则在 EAX 寄存器(假设它不是浮点数)。
这意味着一个 func(1, 2, 3); 调用将生成以下内容:
6A 03 push 3 6A 02 push 2 6A 01 push 1 E8 XX XX XX XX call func
将所有内容放在一起
假设 func()只是对参数进行加法并返回结果,它 可能看起来像这样:
int __cdecl func(int, int, int):<>> prologue: 55 push ebp ; save base pointer 8B EC mov ebp, esp ; new stack frame body: 8B 45 08 mov eax, [ebp+8] ; load first argument to EAX (return value) 03 45 0C add eax, [ebp+0Ch] ; add 2nd argument 03 45 10 add eax, [ebp+10h] ; add 3rd argument epilogue: 5D pop ebp ; restore base pointer C3 retn ; return to caller现在,如果你一直在关注但仍然感到困惑,那么你 可能会问自己以下两个问题之一:
1)为什么要调整 EBP8 点 到达第一个参数?
- 如果你 定义 检查的 call我们之前提到的指令,你会意识到,在内部, 它实际上推动 EIP到 堆栈。 如果您还检查了定义 push, 你会发现它会减少 ESP (它被复制到 EBP序言之后)4 个字节。 另外,序言的第一个 指令也是一个 push, 所以 我们最终得到 4 减 2,因此需要加 8。
2)序言和尾声发生了什么,为什么? 看起来“被截断”了?
- 这只是因为我们在这期间没有使用过堆栈 执行我们的函数 - 如果您注意到的话,我们没有修改 ESP在 all,这意味着我们也不需要恢复它。
如果条件
为了演示流量控制汇编指令,我想添加一个 更多示例展示如何将 if 条件编译为程序集。
假设我们有以下函数:
void print_equal(int a, int b) {
if (a == b) {
printf("equal");
}
else {
printf("nah");
}
}
编译完成后,这是我在帮助下得到的反汇编结果 的 国际开发协会 :
void __cdecl print_equal(int, int):<>> 10000000 55 push ebp 10000001 8B EC mov ebp, esp 10000003 8B 45 08 mov eax, [ebp+8] ; load 1st argument 10000006 3B 45 0C cmp eax, [ebp+0Ch] ; compare it with 2nd ┌┅ 10000009 75 0F jnz short loc_1000001A ; jump if not equal ┊ 1000000B 68 94 67 00 10 push offset aEqual ; "equal" ┊ 10000010 E8 DB F8 FF FF call _printf ┊ 10000015 83 C4 04 add esp, 4 ┌─┊─ 10000018 EB 0D jmp short loc_10000027 │ ┊ │ └ loc_1000001A: │ 1000001A 68 9C 67 00 10 push offset aNah ; "nah" │ 1000001F E8 CC F8 FF FF call _printf │ 10000024 83 C4 04 add esp, 4 │ └── loc_10000027: 10000027 5D pop ebp 10000028 C3 retn给自己一点时间,尝试理解这个反汇编 输出(为了简单起见,我更改了真实地址和 使函数从 10000000 反而)。
如果您想知道 add esp, 4 部分,只是需要调整 ESP后退 到其初始值(与 pop, 除非不修改任何寄存器),因为我们必须 push这 printf 字符串参数。
基本数据结构
现在让我们继续讨论数据是如何存储的(整数和 特别是字符串)。
字节顺序
字节顺序 是表示中的值的字节序列的顺序 电脑内存。
有两种类型 - 大端和小端:

作为参考,x86 系列处理器(几乎所有 您可以找到的计算机)始终使用小端。
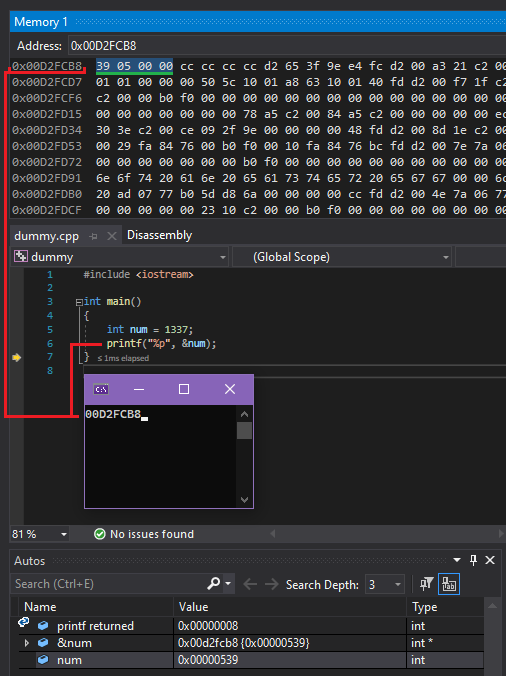
为了给你一个这个概念的生动例子,我编译了一个视觉 Studio C++ 控制台应用程序,我在其中声明了 int 带有值的变量 1337 分配给它,然后我使用打印变量的地址 printf(), 在主要功能上。
然后我运行附加到调试器的程序以检查 内存十六进制视图上打印变量的地址,这是 我得到的结果:
详细说明这一点 - int变量的长度为 4 个字节(32 位)(如果您不知道的话),所以 这意味着如果变量从地址开始 D2FCB8它 会在之前结束 D2FCBC (+4)。
要将人类可读值转换为内存字节,请按照下列步骤操作:
小数: 1337-> 十六进制: 539-> 字节: 00 00 05 39 -> 小端: 39 05 00 00
有符号整数
这部分很有趣但相对简单。 你应该知道什么 这是通常完成的整数签名(正/负) 在计算机上借助一个称为 二进制补码 。
它的要点是整数的最低/前半部分是 保留为正数,而最高/后半部分用于 负数,对于 32 位来说,这是十六进制的样子 有符号整数(突出显示=十六进制,括号内=十进制):
优点 (1/2): 00000000 (0) -> 7FFFFFFF (2,147,483,647 或 INT_MAX)
负面(2/2): 80000000 (-2,147,483,648 或 INT_MIN) -> FFFFFFFF (-1)
如果您注意到的话,我们的价值总是 在上升 。 无论 我们以十六进制或十进制上升。 这就是关键点 概念 - 算术运算不必做任何特殊的事情 为了处理签名,他们可以简单地将所有值视为 无符号/正数,结果仍会被解释 正确(只要我们不超出 INT_MAX或者 INT_MIN), 那是因为整数也会 “翻转 ” 设计上溢/下溢,有点像模拟里程表。
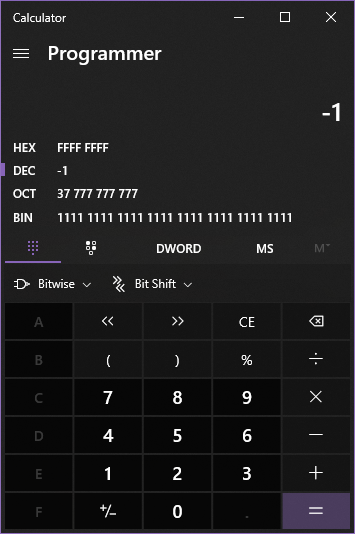
专业提示 :Windows 计算器是一个非常有用的工具 - 您可以将其设置为 程序员模式并将大小设置为DWORD(4字节),然后输入 负十进制值并以十六进制和二进制形式可视化它们,以及 享受对它们进行操作的乐趣。
弦乐
在 C 中,字符串存储为 char数组,因此,这里没有什么特别需要注意的,除了 称为空终止的东西。
如果你想知道如何 strlen()能够知道字符串的大小,很简单——strings 有一个字符表明它们的结束,那就是 null 字节/字符 - 00或者 '\0'。
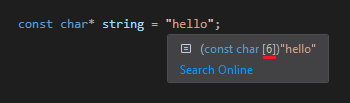
如果您在 C 代码中声明一个字符串常量,并将鼠标悬停在它上面 例如,Visual Studio,它会告诉您 生成的数组,正如您所看到的,因此,它是一个 元素超过“可见”字符串大小。
注意 :字节顺序概念不适用于数组,仅适用于 单一变量。 因此,字符在内存中的顺序是 这里是正常的——从低到高。
理解 call和 jmp 指示
现在您已经了解了所有这些,您可能可以开始制作 感知一些机器代码,并用你的大脑模拟 CPU, 可以这么说,在某种程度上。
让我们以 print_equal() 示例 ,但我们只关注 printf() call 这次的指示。
void print_equal(int, int): ... 10000010 E8 DB F8 FF FF call _printf ... 1000001F E8 CC F8 FF FF call _printf您可能想知道 - 等一下,如果这些是 相同的指令,那么为什么它们的字节不同呢?
那是因为, call(和 jmp) 指令(通常)采用 偏移量 (相对地址)作为 一个参数,而不是绝对地址。
偏移量基本上是当前位置之间的差异, 和目的地,这也意味着它可以是负数 或积极。
如您所见, 操作码 的一个 call 采用 32 位偏移量的指令是 E8, 并且是 接下来是所述偏移量 - 这使得完整的指令: E8 XX XX XX XX。
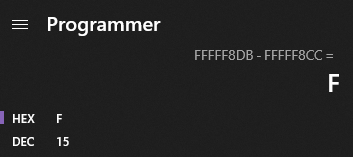
拿出你的计算器, 为什么这么早就关门了?! 并计算 两条指令的偏移量之间的差异(不要忘记 字节序)。
您会注意到这个差异(的绝对值)是 与指令地址之间的地址相同( 1000001F - 10000010= F):
我们应该添加的另一个小细节是 CPU 仅在完全“读取”指令后才执行指令,这意味着 当CPU开始“执行”时, EIP(这 指令指针)已经指向 下一条 要执行的指令。
这就是为什么这些抵消实际上解释了这种行为, 这意味着为了获得 真实 的地址 函数,我们还必须 添加 目标 call 说明:5.
现在让我们应用所有这些步骤来解决 printf()的 示例中第一条指令的地址:
10000010 E8 DB F8 FF FF call _printf
1) 从指令中提取偏移量: E8 (DB F8 FF FF) -> FFFFF8DB (-1829)
2)将其添加到指令地址: 10000010+ FFFFF8DB= 0FFFF8EB
3)最后,添加指令大小: 0FFFF8EB+ 5 = 0FFFF8F0 ( &printf)
完全相同的原理也适用于 jmp 操作说明:
... ┌─── 10000018 EB 0D jmp short loc_10000027 ... └── loc_10000027: 10000027 5D pop ebp ...这个例子中唯一的区别是 EB XX 是一个 简洁版本 jmp 指令 - 这意味着它只需要 8 位(1 字节)偏移量。
所以: 10000018+ 0D+ 2 = 10000027
结论
就是这样! 您现在应该有足够的信息(希望, 动机)开始您的逆向工程可执行文件之旅。
首先编写虚拟 C 代码,编译它,然后调试它 单步执行反汇编指令 (Visual Studio 顺便说一下,允许你这样做)。
编译器资源管理器 也是一个非常有用的网站,它将 C 代码编译为 使用多个编译器为您实时汇编(选择 x86 msvc 适用于 Windows 32 位的编译器)。
之后,您可以尝试使用闭源原生 二进制文件,借助反汇编程序,例如 吉德拉 和 IDA 和调试器,例如 x64dbg 。
注意 :如果您发现信息不准确或有改进的空间 关于这篇文章,并且想改进它,请随时 提交拉取请求 在 GitHub 上。
From 0x44.cc