用 500 行 Python 编写一个 C 编译器
代码太多,我无法在一篇博文中全面涵盖 2 ,所以我将概述我所做的决定、我必须删除的内容以及编译器的总体架构,并涉及每个部分的代表性部分。 希望读完这篇文章后, 代码 会更容易理解!
决定,决定
第一个也是最关键的决定是,这将是一个 单遍 编译器。 500 行对于定义和转换抽象语法树来说太空闲了! 这意味着什么?
大多数编译器:摆弄语法树
嗯,大多数编译器的内部结构看起来像这样:
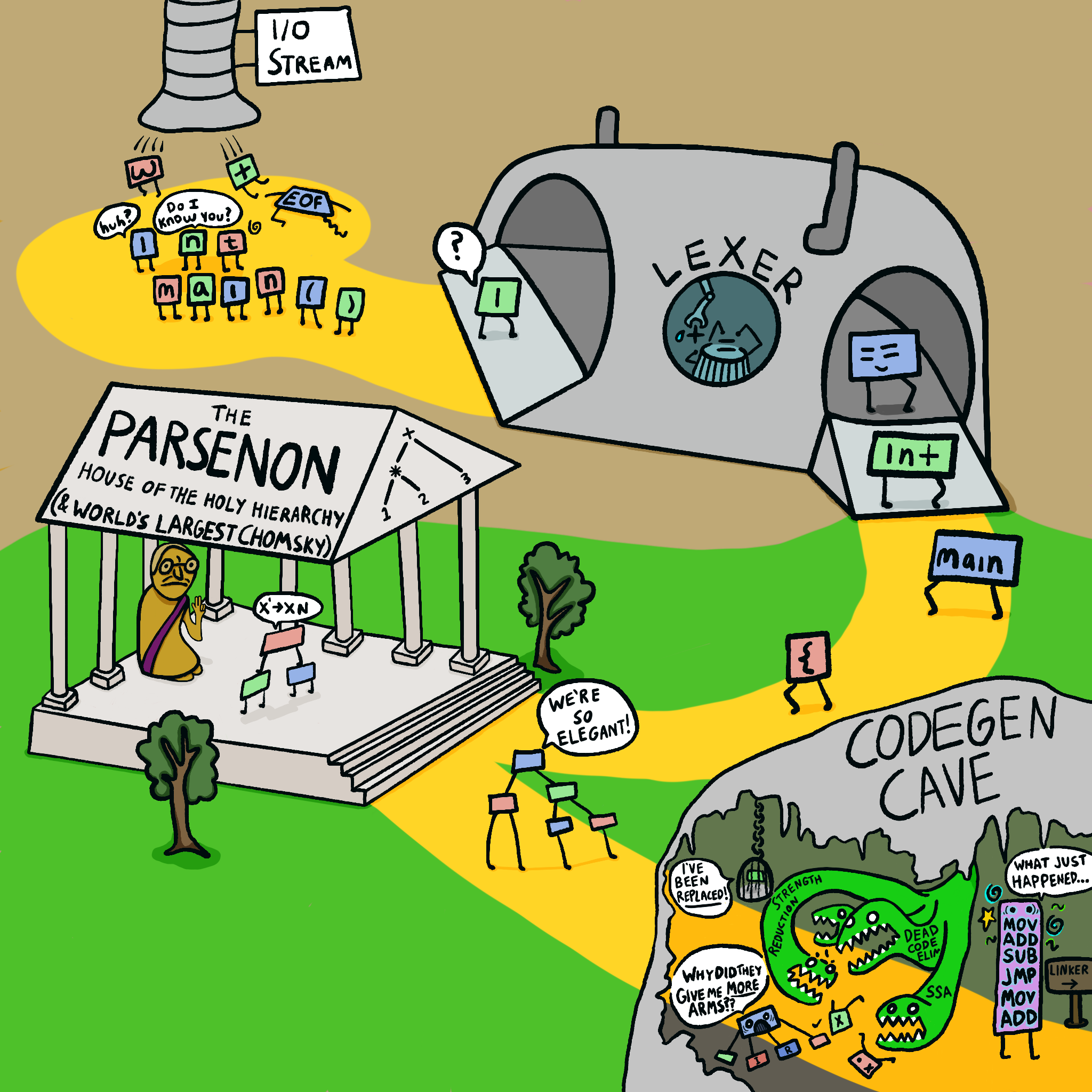
标记被词法分析,然后 解析器 运行它们并构建相当小的语法树:
# hypothetical code, not from anywhere
def parse_statement(lexer) -> PrettyLittleSyntaxTree:
...
if type := lexer.try_next(TYPE_NAME):
variable_name = lexer.next(IDENTIFIER)
if lexer.try_next("="):
initializer = parse_initializer(lexer)
else:
initializer = None
lexer.next(SEMICOLON)
return VariableDeclarationNode(
type = type,
name = variable_name,
initializer = initializer,
)
...
# much later...
def emit_code_for(node: PrettyLittleSyntaxTree) -> DisgustingMachineCode:
...
if isinstance(node, VariableDeclarationNode):
slot = reserve_stack_space(node.type.sizeof())
add_to_environment(node.name, slot)
if node.initializer is not None:
register = emit_code_for(node.initializer)
emit(f"mov {register}, [{slot}]")
...
这里重要的是有 两遍 ,首先解析构建语法树,然后第二遍咀嚼该树并将其转换为机器代码。 这对于大多数编译器来说确实很有用! 它将解析和代码生成分开,因此每个都可以独立发展。 这还意味着您可以在使用语法树生成代码之前对其进行转换 - 例如,通过对其应用优化。 事实上,大多数编译器 都有多个级别的“中间表示”! 在语法树和代码生成之间
这真的很棒,很好的工程,最佳实践,专家推荐等等。 但是……它需要太多代码,所以我们做不到。
相反,我们将进行 单遍 :代码生成 在解析期间 发生。 我们解析一点,发出一些代码,再解析一点,发出更多代码。 例如,这里有一些真实的代码 c500用于解析前缀的编译器 ~操作:
# lexer.try_next() checks if the next token is ~, and if so, consumes
# and returns it (truthy)
elif lexer.try_next("~"):
# prefix() parses and generates code for the expression after the ~,
# and load_result emits code to load it, if needed
meta = load_result(prefix())
# immediately start yeeting out the negation code!
emit("i32.const 0xffffffff")
emit("i32.xor")
# webassembly only supports 32bit types, so if this is a smaller type,
# mask it down
mask_to_sizeof(meta.type)
# return type information
return meta
请注意,没有语法树,没有 PrefixNegateOp节点。 我们看到一些令牌,立即吐出相应的指令。
您可能已经注意到这些指令是 WebAssembly ,它引导我们进入下一部分......
出于某种原因使用 WebAssembly?
所以我决定让编译器以 WebAssembly 为目标。 老实说,我不知道为什么要这么做,这并没有让事情变得更容易——我想我只是好奇? WebAssembly 是一个非常奇怪的目标,尤其是对于 C 来说。 除了一些外部问题(比如在我意识到 WebAssembly v2 与 WebAssembly v1 非常不同之前花了很多时间感到困惑)之外,指令集本身也很 奇怪 。
其一,没有 goto 。 相反,您有块(结构化汇编,想象一下!)和跳转到特定嵌套级别块的开头或结尾的“中断”指令。 这对于 if和 while,但实施了 for 非常 被诅咒,我们稍后再讨论。
此外,WebAssembly 没有寄存器,它有一个堆栈,并且是一个堆栈机。 起初你可能会觉得这很棒,对吧? C需要一个堆栈! 我们可以使用 WebAssembly 堆栈作为我们的 C 堆栈! 不可以,因为您无法引用 WebAssembly 堆栈。 需要维护自己的内存堆栈 因此,我们无论如何都 ,然后将其移入和移出 WASM 参数堆栈。
所以最后,我认为我最终得到的 稍多 代码比针对 x86 或 ARM 等更普通的 ISA 所需的代码 。 但这很有趣! 理论上,您可以运行用以下代码编译的代码 c500在浏览器中,虽然我还没有尝试过(我只是使用 wasmer命令行界面)。
错误处理
基本上没有。 有一个功能 die,当发生任何奇怪的事情并转储编译器堆栈跟踪时,就会调用它 - 如果幸运的话,您会得到一个行号和一条有点模糊的错误消息。
------------------------------<>> File "...compiler.py", line 835, in <module> compile("".join(fi)) # todo: make this line-at-a-time? File "...compiler.py", line 823, in compile global_declaration(global_frame, lexer) <snip> File "...compiler.py", line 417, in value var, offset = frame.get_var_and_offset(varname) File "...compiler.py", line 334, in get_var_and_offset return self.parent.get_var_and_offset(name) File "...compiler.py", line 336, in get_var_and_offset die(f"unknown variable {n}", None if isinstance(name, str) else name.line) File "...compiler.py", line 14, in die traceback.print_stack() ------------------------------ error on line 9: unknown variable c
Rust 编译器,这不是:-)
丢弃什么
最后,我必须决定 不 C 语言放入 500 行是不可行的 支持哪些内容,因为将所有 。 (对不起!) 我决定需要一个真正不错的功能样本来测试一般实现方法的能力,例如,如果我跳过了指针,我就可以摆脱 WASM 参数堆栈并摆脱很多复杂性,但是那会感觉像作弊。
我最终实现了以下功能:
- 算术运算和二元运算符,具有适当的优先级
- int, short, 和 char类型
- 字符串常量(带转义)
- 指针(无论多少层),包括正确的指针算术(递增 int*添加 4)
- 数组(仅单级,不 int[][])
- 功能
- typedefs(以及词法分析器 hack!)
值得注意的是,它不支持:
- 结构:-(可以使用更多代码,基础知识就在那里,我只是无法将其压缩
- 枚举/联合
- 预处理器指令(这本身可能有 500 行......)
- 浮点。 也将是可能的,即 wasm_type东西已经进去了,只是又挤不进去
- 8 字节类型( long/ long long或者 double)
- 其他一些小事情,例如预/后火化、就地初始化等,这些都不太合适
- 任何类型的标准库或 I/O 不返回整数 main()
- 铸造表达式
中的 34/220 个测试用例 编译器通过了c-testsuite 。 对我来说更重要的是,它可以成功编译并运行以下程序:
int swap(int* a, int* b) {
int t;
t = *a; *a = *b; *b = t;
return t;
}
int fib(int n) {
int a, b;
for (a = b = 1; n > 2; n = n - 1) {
swap(&a, &b);
b = b + a;
}
return b;
}
int main() {
return fib(10); // 55
}
好的,关于决定事情就够了,让我们进入代码吧!
助手类型
编译器使用一小部分辅助类型和类。 它们都不是特别奇怪,所以我会很快跳过它们。
Emitter ( 编译器.py:21 )
这是一个单例帮助器,用于发出格式良好的 WebAssembly 代码。
WebAssembly,至少文本格式,被格式化为 s 表达式,但单个指令不需要加括号:
(module
;; <snip...>
(func $swap
(param $a i32)
(param $b i32)
(result i32)
global.get $__stack_pointer ;; prelude -- adjust stack pointer
i32.const 12
i32.sub
;; <snip...>
)
)
Emitter 只是有助于发出具有良好缩进的代码,因此更易于阅读。 它还有一个 no_emit方法,稍后将用于丑陋的黑客攻击 - 请继续关注!
字符串池 ( 编译器.py:53 )
StringPool保存所有字符串常量,以便将它们排列在连续的内存区域中,并将地址分配给代码生成器使用。 当你写的时候 char *s = "abc"在 c500,真正发生的是:
- StringPool附加一个空终止符
- StringPool检查它是否已经存储 "abc",如果是这样,只需返回该地址
- 否则, StringPool将其与基地址 + 到目前为止存储的总字节长度一起添加到字典中 - 这个新字符串在池中的地址
- StringPool手 的 回应
- 当所有代码编译完成后,我们创建一个 rodata带有巨大串联字符串的部分 StringPool,存储在字符串池基地址(追溯使所有地址 StringPool已发放有效)
Lexer ( 编译器.py:98 )
这 Lexer类很复杂,因为 C 的词法分析很复杂 ( (\\([\\abfnrtv'"?]|[0-7]{1,3}|x[A-Fa-f0-9]{1,2}))是该代码中用于字符转义的真正正则表达式) ,但概念上很简单:词法分析器继续识别当前位置的标记是什么。 调用者可以查看该令牌,也可以使用 next告诉词法分析器前进,“消耗”该令牌。 它还可以使用 try_next仅当下一个标记是某种类型时才有条件前进 - 基本上, try_next是一个快捷方式 if self.peek().kind == token: return self.next()。
由于所谓的 “词法分析器黑客”, 还有一些额外的复杂性。 本质上,在解析 C 时,您想知道某个东西是类型名称还是变量名称(因为上下文对于编译某些表达式很重要),但它们之间没有语法区别: int int_t = 0;是完全有效的 C,因为 typedef int int_t; int_t x = 0;。
知道是否有任意标记 int_t是类型名称或变量名称,我们需要将类型信息从解析/代码生成阶段返回到词法分析器中。 对于想要保持其词法分析器、解析器和代码生成模块纯净且独立的常规编译器来说,这是一个巨大的痛苦,但实际上对我们来说并不难! 当我们到达时我会进一步解释它 typedef部分,但基本上我们只是保留 types: set[str]在 Lexer,并且在词法分析时,在赋予令牌类型之前检查令牌是否在该集合中:
if m := re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*", self.src[self.loc :]):
tok = m.group(0)
...
# lexer hack
return Token(TOK_TYPE if tok in self.types else TOK_NAME, tok, self.line)
CType ( 编译器.py:201 )
这只是一个数据类,用于表示有关 C 类型的信息,就像您编写的那样 int **t或者 short t[5]或者 char **t[17],减去 t。
它包含了:
- 类型的名称(已解析的任何类型定义),例如 int或者 short
- 指针的级别是( 0= 不是指针, 1= int *t, 2= int **t, 等等)
- 数组大小是多少( None= 不是数组, 0= int t[0], 1= int t[1], 等等)
值得注意的是,如前所述,这种类型仅支持单级数组,而不支持嵌套数组,例如 int t[5][6]。
FrameVar和 StackFrame ( 编译器.py:314 )
这些类处理我们的 C 堆栈帧。
正如我之前提到的,因为您无法引用 WASM 堆栈,所以我们必须手动处理 C 堆栈,我们不能使用 WASM 堆栈。
为了设置C堆栈,前奏发出了 __main__设立全球 __stack_pointer变量,然后每次函数调用都会减少函数参数和局部变量所需的空间——由该函数的 StackFrame实例。
当我们开始解析函数时,我将更详细地介绍该计算的工作原理,但本质上,每个参数和局部变量都会在该堆栈空间中获得一个槽,并增加 StackFrame.frame_size(以及 下一个 变量的偏移量)取决于它的大小。 每个参数和局部变量的偏移量、类型信息和其他数据都存储在 FrameVar例如,在 StackFrame.variables,按声明顺序。
ExprMeta ( 编译器.py:344 )
这个最终数据类用于跟踪表达式的结果是 值 还是 位置 。 我们需要跟踪这种区别,以便根据某些表达式的使用方式以不同的方式处理它们。
例如,如果你有一个变量 x类型的 int,它可以通过两种方式使用:
- x + 1想要 值 的 x, 说 1, 进行操作
- &x想要 地址 _ x, 说 0xcafedead
当我们解析 x表达式,我们可以轻松地从堆栈帧中获取地址:
# look the variable up in the `StackFrame`
var, offset = frame.get_var_and_offset(varname)
# put the base address of the C stack on top of the WASM stack
emit(f"global.get $__stack_pointer")
# add the offset (in the C stack)
emit(f"i32.const {offset}")
emit("i32.add")
# the address of the variable is now on top of the WASM stack
但现在怎么办? 要是我们 i32.load 这个地址来获取值,然后 &x 将无法获取地址。 但如果我们不加载它,那么 x + 1 会尝试给地址加一,结果是 0xcafedeae 代替 2!
那就是那里 ExprMeta进来:我们将地址留在堆栈上,并返回一个 ExprMeta表明这是一个 地方 :
return ExprMeta(True, var.type)
然后,对于像这样的操作 + 总是想对值而不是位置进行操作,有一个函数 load_result将任何位置转换为值:
def load_result(em: ExprMeta) -> ExprMeta:
"""Load a place `ExprMeta`, turning it into a value
`ExprMeta` of the same type"""
if em.is_place:
# emit i32.load, i32.load16_s, etc., based on the type
emit(em.type.load_ins())
return ExprMeta(False, em.type)
...
# in the code for parsing `+`
lhs_meta = load_result(parse_lhs())
...
同时,像这样的操作 & 只是不加载结果,而是将地址留在堆栈上:在重要意义上, &在我们的编译器中是无操作,因为它不发出任何代码!
if lexer.try_next("&"):
meta = prefix()
if not meta.is_place:
die("cannot take reference to value", lexer.line)
# type of &x is int* when x is int, hence more_ptr
return ExprMeta(False, meta.type.more_ptr())
另请注意,尽管是一个 地址 ,但结果 & 不是 一个地方! (该代码返回一个 ExprMeta和 is_place=False.) 的结果 &应该被视为一个值,因为 &x + 1 应该 添加 1(更确切地说, sizeof(x)) 到地址。 这就是为什么我们需要区分位置/值,因为仅仅“作为地址”不足以知道是否应该加载表达式的结果。
好的,关于辅助类就足够了。 让我们继续讨论 Codegen 的核心部分!
解析和代码生成
编译器的一般控制流程是这样的:

蓝色矩形代表编译器的主要功能—— __main__, compile(), global_declaration(), statement(), 和 expression()。 底部的长方形链显示了运算符的优先级 - 然而,大多数这些函数都是由高阶函数自动生成的!
我将逐一浏览蓝色方块并解释每个方块中有趣的内容。
__main__ ( 编译器.py:827 )
这一篇非常短而且乏味。 这是完整的:
if __name__ == "__main__":
import fileinput
with fileinput.input(encoding="utf-8") as fi:
compile("".join(fi)) # todo: make this line-at-a-time?
显然我从未完成那个 TODO! 这里唯一真正有趣的是 fileinput模块,您可能没有听说过。 从模块文档中,
典型用途是:
import fileinput
for line in fileinput.input(encoding="utf-8"):
process(line)
这会迭代 sys.argv[1:] 中列出的所有文件的行, 如果列表为空,则默认为 sys.stdin。 如果文件名是“-” 也被 sys.stdin 和可选参数 mode 和 开钩被忽略。 要指定文件名的替代列表, 将其作为参数传递给 input()。 也允许使用单个文件名。
这意味着,从技术上来说, c500支持多个文件! (如果你不介意它们全部连接起来并且行号混乱:-) fileinput实际上相当复杂并且有一个 filelineno()方法,我只是出于空间原因没有使用它。)
compile() ( 编译器.py:805 )
compile()是这里第一个有趣的函数,并且足够短,还可以逐字包含:
def compile(src: str) -> None:
# compile an entire file
with emit.block("(module", ")"):
emit("(memory 3)")
emit(f"(global $__stack_pointer (mut i32) (i32.const {PAGE_SIZE * 3}))")
emit("(func $__dup_i32 (param i32) (result i32 i32)")
emit(" (local.get 0) (local.get 0))")
emit("(func $__swap_i32 (param i32) (param i32) (result i32 i32)")
emit(" (local.get 1) (local.get 0))")
global_frame = StackFrame()
lexer = Lexer(src, set(["int", "char", "short", "long", "float", "double"]))
while lexer.peek().kind != TOK_EOF:
global_declaration(global_frame, lexer)
emit('(export "main" (func $main))')
# emit str_pool data section
emit(f'(data $.rodata (i32.const {str_pool.base}) "{str_pool.pooled()}")')
该函数处理发出模块级前奏。
首先,我们为 WASM VM 发出一个编译指示以保留 3 页内存( (memory 3)),然后我们将堆栈指针设置为从该保留区域的末尾开始(它将向下增长)。
然后,我们定义两个堆栈操作助手 __dup_i32和 __swap_i32。 如果您曾经使用过 Forth,这些应该很熟悉: dup复制 WASM 堆栈顶部的项目 ( a -- a a) ,以及 swap交换 WASM 堆栈上前两项的位置 ( a b -- b a) 。
接下来,我们初始化一个堆栈帧来保存全局变量,使用词法分析器黑客的内置类型名初始化词法分析器,并咀嚼全局声明,直到用完为止!
最后我们导出 main并转储字符串池。
global_declaration() ( 编译器.py:743 )
这个函数太长,无法内联整个函数,但签名如下所示:
def global_declaration(global_frame: StackFrame, lexer: Lexer) -> None:
# parse a global declaration -- typedef, global variable, or function.
...
它处理 typedef、全局变量和函数。
Typedef 很酷,因为这是词法分析器黑客发生的地方!
if lexer.try_next("typedef"):
# yes, `typedef int x[24];` is valid (but weird) c
type, name = parse_type_and_name(lexer)
# lexer hack!
lexer.types.add(name.content)
typedefs[name.content] = type
lexer.next(";")
return
我们重用了通用的类型名称解析工具,因为 typedef 继承了所有 C 奇怪的“声明反映用法”规则,这对我们来说很方便。 (对于困惑的新手来说就不那么重要了!) 然后我们通知词法分析器我们发现了一个新的类型名称,以便将来该标记将被词法分析为类型名称而不是变量名称。
最后,对于 typedef,我们将类型存储在全局 typedef 注册表中,使用尾随分号,然后返回 compile()以便下一次全球宣言。 重要的是,我们存储的类型是一个 完整解析的类型 ,因为如果你这样做 typedef int* int_p;然后稍后写 int_p *x, x应该得到一个结果类型 int**——指针等级是累加的! 这意味着我们不能只存储基本 C 类型名,而是需要存储整个 CType。
如果声明 不是 typedef,我们将解析变量类型和名称。 如果我们找到一个 ;token 我们知道它是一个全局变量声明(因为我们不支持全局初始值设定项)。 在这种情况下,我们将全局变量添加到全局堆栈帧和 bail 中。
if lexer.try_next(";"):
global_frame.add_var(name.content, decl_type, False)
return
然而,如果没有分号,我们肯定正在处理一个函数。 要生成函数代码,我们需要:
- 制作一个新的 StackFrame对于函数,命名为 frame
- 然后,解析所有参数并将它们存储在框架中 frame.add_var(varname.content, type, is_parameter=True)
- 之后,解析所有变量声明 variable_declaration(lexer, frame),这将它们添加到 frame
- 现在我们知道函数的堆栈帧需要有多大( frame.frame_size),这样我们就可以开始发出前奏了!
- 首先,对于堆栈帧中的所有参数(添加 is_parameter=True),我们生成 WASM param声明,以便可以使用 WASM 调用约定来调用该函数(在 WASM 堆栈上传递参数):
for v in frame.variables.values():
if v.is_parameter:
emit(f"(param ${v.name} {v.type.wasmtype})")
- 然后,我们可以发出一个 result 返回类型的注释,并调整 C 堆栈指针以为函数的参数和变量腾出空间:
emit(f"(result {decl_type.wasmtype})")
emit("global.get $__stack_pointer")
# grow the stack downwards
emit(f"i32.const {frame.frame_offset + frame.frame_size}")
emit("i32.sub")
emit("global.set $__stack_pointer")
- 对于每个参数(按相反顺序,因为堆栈),将其从 WASM 堆栈复制到我们的堆栈:
for v in reversed(frame.variables.values()):
if v.is_parameter:
emit("global.get $__stack_pointer")
emit(f"i32.const {frame.get_var_and_offset(v.name)[1]}")
emit("i32.add")
# fetch the variable from the WASM stack
emit(f"local.get ${v.name}")
# and store it at the calculated address in the C stack
emit(v.type.store_ins())
- 最后,我们可以调用 statement(lexer, frame) 在 codegen 的循环中生成函数中的所有语句,直到我们到达右括号:
while not lexer.try_next("}"):
statement(lexer, frame)
- 奖励步骤:我们假设该函数总是有一个 return ,所以我们 emit("unreachable") 所以 WASM 分析器不会崩溃。
缂! 那是很多。 但这就是函数的全部内容,因此对于 global_declaration(),所以让我们继续 statement()。
statement() ( 编译器.py:565 )
里面有很多代码 statement()。 不过,大部分都是相当重复的,所以我只是解释一下 while和 for,这应该给出一个很好的概述。
还记得 WASM 没有跳转,而是有结构化控制流吗? 现在这很重要。
首先,让我们看看它是如何工作的 while,这并不算太麻烦。 WASM 中的 while 循环如下所示:
block
loop
;; <test>
i32.eqz
br_if 1
;; <loop body>
br 0
end
end
正如您所看到的,有两种类型的块 - block和 loop(还有一个 if块类型,我没有使用)。 每个语句都包含一定数量的语句,然后以 end。 在一个块内,你可以用 br,或者有条件地基于 WASM 堆栈的顶部 br_if(还有 br_table,我没有使用)。
这 brfamily 接受一个 labelidx 参数,这里要么 1或者 0,这是该操作适用于哪个级别的块。 所以在我们的 while 循环中, br_if 1适用于外部块——索引 1,而 br 0适用于内部块 - 索引 0。 (索引始终与相关指令相关 - 0 是 该指令的 最内部块。)
最后,要知道的最后一条规则是 br在一个 block跳到 向前 结尾 block,而一个 br在一个 loop跳转 向后 到开头 loop。
所以希望 while 循环代码现在有意义! 再看一遍,
block
loop
;; <test>
i32.eqz
;; if test == 0, jump forwards (1 = labelidx of the `block`),
;; out of the loop
br_if 1
;; <loop body>
;; unconditionally jump backwards (0 = labelidx of the `loop`).
;; to the beginning of the loop
br 0
end
end
在更正常的装配中,这对应于:
.loop_start ;; <test> jz .block_end ;; <loop body> jmp .loop_start .block_end
但是通过跳跃,您可以表达在 WASM 中无法(轻松)表达的内容 - 例如,您可以跳到块的中间。
(这主要是编译C的问题 goto,我什至没有尝试过——有一种算法可以使用以下方式转换任何代码 goto到使用结构化控制流的等效程序中,但它很复杂,而且我认为它不适用于我们的单遍方法。)
但对于 while 循环来说,这还不算太糟糕。 我们所要做的就是:
# `emit.block` is a context manager to emit the first parameter ("block" here),
# and then the second ("end") on exit
with emit.block("block", "end"):
with emit.block("loop", "end"):
# emit code for the test, ending with `i32.eqz`
parenthesized_test()
# emit code to exit the loop if the `i32.eqz` was true
emit("br_if 1")
# emit code for the body
bracketed_block_or_single_statement(lexer, frame)
# emit code to jump back to the beginning
emit("br 0")
但对于 for 循环,它会变得令人讨厌。 考虑这样的 for 循环:
for (i = 0; i < 5; i = i + 1) {
j = j * 2 + i;
}
词法分析器/代码生成器看到 for 循环各部分的顺序是:
- i = 0
- i < 5
- i = i + 1
- j = j * 2 + i
但为了使用 WASM 的结构化控制流,我们需要将它们放入代码中的顺序是:
block
;; < code for `i = 0` (1) >
loop
;; < code for `i < 5` (2) >
br_if 1
;; < code for `j = j * 2 + i` (4!) >
;; < code for `i = i + 1` (3!) >
br 0
end
end
请注意,3 和 4 在生成的代码中颠倒了,顺序为 1、2、4、3。 这是单遍编译器的问题! 与普通编译器不同,我们无法存储高级语句以供以后使用。 或者……我们可以吗?
我最终处理这个问题的方法是使词法分析器 可克隆 后重新解析进度语句 ,并在 解析主体 。 本质上,代码如下所示:
elif lexer.try_next("for"):
lexer.next("(")
with emit.block("block", "end"):
# parse initializer (i = 0)
# (outside of loop since it only happens once)
if lexer.peek().kind != ";":
expression(lexer, frame)
emit("drop") # discard result of initializer
lexer.next(";")
with emit.block("loop", "end"):
# parse test (i < 5), if present
if lexer.peek().kind != ";":
load_result(expression(lexer, frame))
emit("i32.eqz ;; for test")
emit("br_if 1 ;; exit loop")
lexer.next(";")
# handle first pass of advancement statement, if present
saved_lexer = None
if lexer.peek().kind != ")":
saved_lexer = lexer.clone()
# emit.no_emit() disables code output inside of it,
# so we can skip over the advancement statement for now
# to get to the for loop body
with emit.no_emit():
expression(lexer, frame)
lexer.next(")")
# parse body
bracketed_block_or_single_statement(lexer, frame)
# now that we parsed the body, go back and re-parse
# the advancement statement using the saved lexer
if saved_lexer != None:
expression(saved_lexer, frame)
# jump back to beginning of loop
emit("br 0")
正如您所看到的,技巧是保存词法分析器,然后使用 它 返回并稍后处理高级语句,而不是像普通编译器那样保存语法树。 不是很优雅——编译 for 循环可能是编译器中最粗糙的代码——但它工作得足够好!
的其他部分 statement()大部分相似,因此我将跳过它们以了解编译器的最后一个主要部分 - expression()。
expression() ( 编译器.py:375 )
expression()是编译器中的最后一个大方法,它处理解析表达式,正如您所期望的那样。 它包含许多内部方法,每个方法对应一个优先级,每个方法返回 ExprMeta前面描述的结构(处理“位置与值”的区别,可以使用 load_result)。
优先级堆栈的底部是 value()(命名有点令人困惑,因为它可以返回 ExprMeta(is_place=True, ...))。 它处理常量、括号表达式、函数调用和变量名。
除此之外,优先级的基本模式是这样的函数:
def muldiv() -> ExprMeta:
# lhs is the higher precedence operation (prefix operators, in this case)
lhs_meta = prefix()
# check if we can parse an operation
if lexer.peek().kind in ("*", "/", "%"):
# if so, load in the left hand side
lhs_meta = load_result(lhs_meta)
# grab the specific operator
op_token = lexer.next()
# the right hand side should use this function, for e.g. `x * y * z`
load_result(muldiv())
# emit an opcode to do the operation
if op_token == "*":
emit(f"i32.mul")
elif op_token == "/":
emit(f"i32.div_s")
else: # %
emit(f"i32.rem_s")
# mask down the result if this is a less-than-32bit type
mask_to_sizeof(lhs_meta.type)
# we produced a value (is_place=False)
return ExprMeta(False, lhs_meta.type)
# if we didn't find a token, just return the left hand side unchanged
return lhs_meta
事实上,这种模式是如此一致,以至于大多数操作,包括 muldiv,不是写出来的,而是由高阶函数定义的 makeop:
# function for generating simple operator precedence levels from declarative
# dictionaries of { token: instruction_to_emit }
def makeop(
higher: Callable[[], ExprMeta], ops: dict[str, str], rtype: CType | None = None
) -> Callable[[], ExprMeta]:
def op() -> ExprMeta:
lhs_meta = higher()
if lexer.peek().kind in ops.keys():
lhs_meta = load_result(lhs_meta)
op_token = lexer.next()
load_result(op())
# TODO: type checking?
emit(f"{ops[op_token.kind]}")
mask_to_sizeof(rtype or lhs_meta.type)
return ExprMeta(False, lhs_meta.type)
return lhs_meta
return op
muldiv = makeop(prefix, {"*": "i32.mul", "/": "i32.div_s", "%": "i32.rem_s"})
...
shlr = makeop(plusminus, {"<<": "i32.shl", ">>": "i32.shr_s"})
cmplg = makeop(
shlr,
{"<": "i32.lt_s", ">": "i32.gt_s", "<=": "i32.le_s", ">=": "i32.ge_s"},
CType("int"),
)
cmpe = makeop(cmplg, {"==": "i32.eq", "!=": "i32.ne"}, CType("int"))
bitand = makeop(cmpe, {"&": "i32.and"})
bitor = makeop(bitand, {"|": "i32.or"})
xor = makeop(bitor, {"^": "i32.xor"})
...
只有少数具有特殊行为的操作需要显式定义,例如 plusminus它需要处理 C 指针数学的细微差别。
就是这样! 这是编译器的最后一个主要部分。
包起来...
这就是我们 在 500 行 Python 中的 C 编译器 之旅! 编译器以复杂而闻名——GCC 和 Clang 非常庞大,甚至 TCC( Tiny C 编译器)也有数万行代码——但如果您愿意牺牲代码质量并一次性完成所有工作,它们可以非常紧凑!
我很想知道您是否编写自己的单遍编译器——也许是针对自定义语言? 我认为这种编译器可能成为自托管语言的一个很好的阶段,因为它非常简单。
下次,这个博客将回到定期安排的法学硕士帖子,其中包含一篇关于手工制作小型变压器的帖子!
MODEL = {
# EMBEDDING USAGE
# P = Position embeddings (one-hot)
# T = Token embeddings (one-hot, first is `a`, second is `b`)
# V = Prediction scratch space
#
# [P, P, P, P, P, T, T, V]
"wte": np.array(
# one-hot token embeddings
[
[0, 0, 0, 0, 0, 1, 0, 0], # token `a` (id 0)
[0, 0, 0, 0, 0, 0, 1, 0], # token `b` (id 1)
]
),
"wpe": np.array(
# one-hot position embeddings
[
[1, 0, 0, 0, 0, 0, 0, 0], # position 0
[0, 1, 0, 0, 0, 0, 0, 0], # position 1
[0, 0, 1, 0, 0, 0, 0, 0], # position 2
[0, 0, 0, 1, 0, 0, 0, 0], # position 3
[0, 0, 0, 0, 1, 0, 0, 0], # position 4
]
),
...: ...
}
如果这听起来很有趣,或者您想看到更多这样的帖子,请考虑 在 Twitter 上关注我 或订阅我的邮件列表以获取新帖子的更新!
From : https://vgel.me/posts/c500/